In the vast realm of web data extraction, two terms frequently surface – web crawler vs web scraper. While they may sound interchangeable, these tools serve distinct purposes in the world of data acquisition from the internet. Let’s embark on a journey to unravel the nuances that differentiate web crawlers from web scrapers and explore their individual functionalities.
Distinctions: Web Crawler vs Web Scrapers:

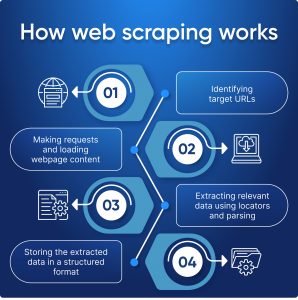
In simple words, web crawler vs web scraper, are two types of data mining used to understand website data and collect website data. So web crawling and web scraping are complementary processes that, when used in tandem, form a comprehensive approach to web data extraction. Web crawling initiates the journey by systematically navigating through the web, and discovering and indexing pages through a network of hyperlinks. Its purpose is to gather pages and create indices for search engines.
Conversely, web scraping follows, honing in on specific pages to download and extract targeted data, such as product details or SEO information. The synergy between these methods is evident in data extraction projects, where both crawling and scraping play pivotal roles.
Web scraping yields raw HTML data subsequently parsed into structured formats like JSON or CSV for meaningful analysis. Together, these techniques empower businesses, researchers, and analysts to glean valuable insights from the vast landscape of the internet.
A web crawler systematically explores websites, following links to index pages, while a web scraper extracts specific data from downloaded pages. Crawlers create indices, aiding search engines, while scrapers retrieve targeted information for analysis. Together, they form a comprehensive approach to web data extraction in various applications.
Understanding Web Crawlers
The Essence of Web Crawling: At its core, a web crawler is akin to a digital spider navigating the intricate web. Its primary mission is to systematically traverse through websites, following links, and indexing information. Think of it as the mechanism behind search engines like Google, which meticulously index the vast expanse of the internet to deliver relevant results when you hit that search button.
Key Characteristics: Web Crawler vs Web Scrapers
- Automated Navigation: Web crawlers autonomously move from one page to another, following links within a website and to other connected sites.
- Indexing: The crawler compiles an index of the visited web pages, creating a structured map of the internet.
- Purposeful Exploration: Crawlers are designed to explore and catalog web pages for search engines, ensuring up-to-date and comprehensive search results.
Use Cases:
- Search Engine Indexing: Web crawlers are integral to the functionality of search engines by constantly updating their indexes for improved search results.
- Data Aggregation: Crawlers can be employed to gather specific data, such as news articles or product information, from various sources.
Demystifying Web Scrapers
The Art of Web Scraping: Contrastingly, a web scraper is more of a digital artisan, meticulously extracting specific information from websites. It’s a tailored tool designed to pluck nuggets of data from web pages, offering a targeted approach to data extraction.
Key Characteristics:
- Focused Data Extraction: Web scrapers are programmed to target and extract particular information, be it prices from e-commerce sites, weather updates, or any other data point.
- Structured Output: Unlike the broad indexing of web crawlers, web scrapers deliver specific, structured data sets tailored to a predefined need.
- Interactivity: Scrapers often interact with a website’s frontend, mimicking human behavior to access desired information.
Use Cases:
- Price Monitoring: Scrapers can track and extract pricing information from e-commerce websites for competitive analysis.
- Content Aggregation: Media outlets often use scrapers to gather news and updates from various sources for publication.
Key Distinctions: Web Crawler vs Web Scrapers
- Scope of Operation:
- Web Crawler: Broad, systematic exploration of the internet, indexing entire websites.
- Web Scraper: Targeted extraction of specific data points from identified sources.
- Level of Automation:
- Web Crawler: Highly automated, traversing links and indexing without specific user instructions.
- Web Scraper: Programmed with precise instructions for focused data extraction.
- Intent and Purpose:
- Web Crawler: Primarily serves search engines, ensuring an up-to-date index for search results.
- Web Scraper: Tailored for specific data needs, supporting applications ranging from market research to content aggregation.
Ethical Considerations:
While both tools are invaluable in the realm of data acquisition, ethical considerations are paramount. Website owners may employ measures like robots.txt files to guide crawlers and scrapers on what is permissible. Respect for these guidelines and adherence to legal and ethical standards are crucial for sustainable and responsible data extraction practices.
Benefits and Drawbacks: Web crawler vs Web scraper
1. Web scraping has several benefits, including speed, large-scale data extraction, cost-effectiveness, flexibility and methodical approach, performance reliability and robustness, low maintenance expenses, and automated structured data delivery.
Nevertheless, a few drawbacks of web scraping are observed. Web scraping can be stopped, has a learning curve, and requires ongoing maintenance.
2. The following benefits of web crawling include simplicity of data collection, increased site traffic, user activity tracking, and essential information tracking.
Even though online crawling sounds easy, there are a few challenges involved: keeping databases up to date; lack of context; irregular topologies; bandwidth and influence on web servers; and emergence of anti-scraping programs.
What is nodejs web scraper and its use:

A Node.js web scraper is a script or application built using the Node.js runtime environment for server-side JavaScript. Leveraging libraries like Cheerio or Puppeteer, Node.js scrapers automate the extraction of data from websites. These tools allow developers to navigate web pages, manipulate HTML content, and retrieve specific information. Node.js web scrapers are efficient for tasks such as data mining, content aggregation, and competitive analysis, offering a versatile and scalable solution for web data extraction.
Node.js web scrapers are employed for diverse applications, including real-time data extraction for analytics, content aggregation for news platforms, monitoring product prices in e-commerce, and automating repetitive web tasks. Their asynchronous nature and scalability make Node.js scrapers ideal for efficient, high-performance data retrieval and processing from the web.
Conclusion:
In essence, web crawler vs web scraper is indispensable tools that complement each other in the vast landscape of web data. While crawlers index the entirety of the internet, scrapers meticulously extract specific gems of information. Whether you’re a search engine optimizing its results or a business seeking targeted insights, understanding the distinctions between these tools is pivotal for navigating the digital landscape effectively. Harnessing the power of both, web crawlers and web scrapers, opens up a realm of possibilities for businesses, researchers, and data enthusiasts alike, ensuring that the vast web is not just explored but also mined for meaningful insights.
See Also:
- Unveiling the Distinctions: Web Crawler vs Web Scrapers
- How to Make Money with Web Scraping Using Python
- How to Type Cast in Python with the Best 5 Examples
- Best Variable Arguments in Python
- 5 Best AI Prompt Engineering Certifications Free
- 5 Beginner Tips for Solving Python Coding Challenges
- Exploring Python Web Development Example Code
- “Python Coding Challenges: Exercises for Success”