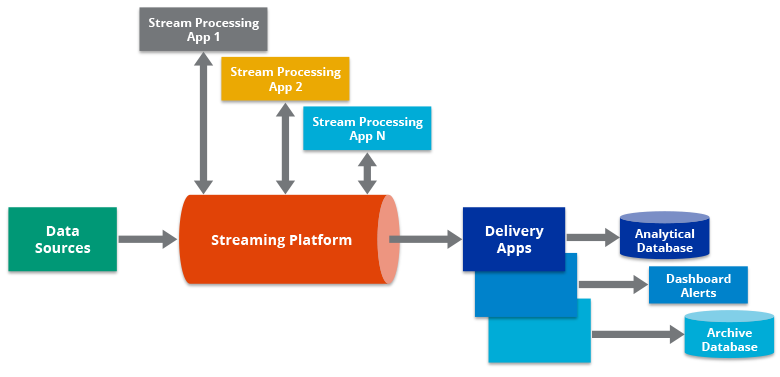
A data pipeline is an approach that involves collecting raw data from different sources, applying transformations, and transferring it to a designated data store, such as a data lake or data warehouse, for analysis. Before being stored, the data typically undergoes various processing operations.
What is Data Pipelines?
A data pipeline is a method used to manage the flow of data from various sources to a central data store, such as a data lake or a data warehouse. In other words, Pipelining data involves breaking down data processing tasks into smaller, sequential steps, enabling the efficient and continuous flow of data through the pipeline for transformation, analysis, and storage.
Let’s break down what this means:
- Ingestion: Raw data is ingested from diverse data sources. These sources can include APIs, SQL and NoSQL databases, files, and more.
- Transformation: The ingested data undergoes processing and transformations. This step ensures that the data is in a suitable format for analysis. Transformations may involve filtering, masking, aggregations, and other operations.
- Destination: The processed data is then ported to a data repository (such as a data lake or data warehouse). These repositories serve as centralized storage for further analysis.
- Data Processing: Before flowing into the repository, data usually undergoes some data processing. This step aligns the data with the repository’s schema, ensuring compatibility.
- Use Cases: Data pipelines are essential for various data projects, including exploratory data analysis, data visualizations, and machine learning tasks.
Now, let’s explore a few types of data pipelines:
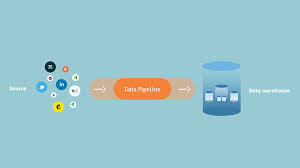
- Batch Processing: This type loads data in batches during scheduled intervals (often off-peak hours). It’s optimal for scenarios where immediate analysis isn’t required (e.g., monthly accounting). Batch processing is associated with the ETL (Extract, Transform, Load) process.
- Real-time Processing: Unlike batch processing, real-time pipelines handle data as it arrives. They’re crucial for applications requiring up-to-the-minute insights.
Remember, data pipelines act as the “piping” for data science projects and business intelligence dashboards, ensuring data flows smoothly and efficiently.
Data Pipeline Development
Data pipeline development refers to the structured approach of moving, transforming, and managing data within a computing environment. It involves three core elements: a source, processing steps, and a destination. The process ensures a systematic flow of data from its origin, through various processing stages, and ultimately to its intended destination.
Data Pipeline Management
Data pipeline management involves overseeing the components and processes that enable the seamless flow of data between a source and a destination. It encompasses tasks such as integrating data, ensuring data quality, and managing metadata. Effective data pipeline management is essential for maintaining a reliable and efficient data flow within an organization.
Data Pipeline Process:
A data pipeline is a series of automated steps that facilitate the movement of raw data from different sources to a designated storage and analysis destination. It serves as an automated representation of the data engineering lifecycle, encompassing data generation, ingestion, processing, storage, and consumption.
Data Pipeline Solutions
Data pipeline solutions help organizations in efficiently handling substantial volumes of data by automating the movement of data from various sources to designated destinations. These solutions enable the integration of data from multiple sources, allowing the creation of comprehensive datasets for business intelligence, data analysis, and other applications. By leveraging data pipelines, organizations can derive valuable insights from their data, such as identifying customer trends and optimizing business processes.
Examples of Data Pipelines:
1. E-commerce Data Pipeline: In this pipeline, data is collected from various sources such as online stores, customer interactions, and marketing campaigns. The data is then processed, transformed, and stored for analysis, enabling insights into customer behavior, sales patterns, and marketing effectiveness.
2. IoT Data Pipeline: This involves collecting sensor data, sending it to a central system or cloud platform, performing real-time processing and analysis, and storing the data for further analysis, predictive maintenance, or anomaly detection.
3. Social Media Data Pipeline: It captures posts, comments, and user interactions, applies sentiment analysis or topic modeling, and stores the processed data for brand monitoring, trend analysis, or personalized recommendations.
4. Log Analytics Pipeline: This involves collecting log files, parsing and extracting relevant information, aggregating and analyzing the data, and generating alerts or reports for troubleshooting, performance monitoring, or security analysis.
5. Financial Data Pipeline: This pipeline deals with financial data from various sources like transaction records, market feeds, or regulatory filings. The data is ingested, validated, transformed, and stored in a structured format for analysis, risk assessment, fraud detection, or compliance reporting.
Data Pipeline Tools
Let’s explore some popular data pipeline tools that facilitate efficient data movement and integration:
1. Astera Centerprise:
-
- Description: An integration platform that includes tools for data integration, transformation, quality, and profiling.
- Features:
- Data integration from various sources.
- Transformation capabilities.
- Data quality checks.
- Profiling for insights.
- Reviews: Highly rated with 45 reviews.
2. Control-M:
-
- Description: A platform for integrating, automating, and orchestrating application and data workflows across complex hybrid technology ecosystems.
- Features:
- Deep operational capabilities.
- Speed, scale, security, and governance.
- Reviews: Well-received with 51 reviews.
3. Skyvia:
-
- Description: A cloud platform for no-coding data integration (both ELT and ETL), automating workflows, and managing data.
- Features:
- Supports major cloud apps and databases.
- Requires no software installation.
- Reviews: Positive feedback with 20 reviews.
4. Apache Airflow:
-
- Description: An open-source tool for programmatically authoring, scheduling, and monitoring data pipelines using Python and SQL.
- Features:
- Flexible workflow management.
- Widely used in the industry.
- Reviews: Well-regarded with 9 reviews.
5. Fivetran:
-
- Description: Replicates applications, databases, events, and files into a high-performance data warehouse.
- Features:
- Fully managed and zero-maintenance pipelines.
- Quick setup.
- Reviews: Positive reception with 7 reviews.
6. Integrate.io:
-
- Description: Allows organizations to integrate, process, and prepare data for analytics on the cloud.
- Features:
- No-code environment.
- Scalable platform for big data opportunities.
- Reviews: Favorable feedback.
Remember that the choice of a data pipeline tool depends on your specific requirements, existing infrastructure, and scalability needs. Each tool offers unique features, so consider evaluating them based on your organization’s context and goals.
An ETL (Extract, Transform, Load) pipeline is a crucial component in the world of data integration. Let’s break down its purpose and characteristics:
1. Purpose of ETL Pipeline:
-
- Data Movement: ETL pipelines facilitate the movement of data from various sources (such as databases, APIs, and files) to a central repository, often a data warehouse.
- Data Transformation: During this process, data is transformed to ensure it aligns with the destination database’s schema and requirements.
- Data Loading: Once transformed, the data is loaded into the target repository, making it available for reporting, analysis, and business insights.
2. Benefits of Pipeline ETL:
-
- Centralization and Standardization: ETL pipelines consolidate data from diverse systems, ensuring a standardized format.
- Developer Efficiency: By automating data movement and maintenance tasks, ETL frees up developers to focus on more meaningful work.
- Legacy System Migration: ETL pipelines assist in migrating data from legacy systems to modern data warehouses.
- Deeper Analytics: After basic transformations, ETL enables deeper insights into the data.
3. Characteristics of Effective ETL Pipelines:
-
- Continuous Data Processing: ETL pipelines should operate continuously, adapting to changing data.
- Elastic and Agile: They need to be flexible and responsive to varying workloads.
- Isolated Processing Resources: Isolation ensures stability and scalability.
- Increased Data Access: ETL pipelines empower decision-makers by providing timely data.
- Ease of Setup and Maintenance: Simplicity is key for successful implementation.
4. ETL Pipeline vs. Data Pipeline:
-
- An ETL pipeline is a specific type of data pipeline.
- While ETL focuses on extraction, transformation, and loading, a data pipeline encompasses a broader set of processes for data movement.
- Data pipelines may not always involve transformation or loading into a destination database; they can trigger other workflows or processes.
In summary, ETL pipelines play a vital role in preparing data for analytics, ensuring smooth data flow, and empowering organizations with actionable insights.
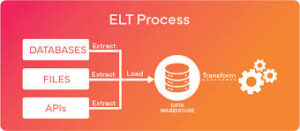
What is a Data Ingestion Pipeline?
A data ingestion pipeline is a crucial component of contemporary data architecture, responsible for transferring data from its source to a central storage or utilization location. It plays a vital role in efficient data management. A basic pipeline involves extracting data from a source, performing data cleaning, and subsequently writing it to a designated destination.
Data Pipeline Python
Let’s explore how to build data pipelines using Python. Data pipelines are essential for transforming raw data into actionable insights. Here are some approaches:
1. Building a Data Pipeline with Python and SQL:
-
- Description: In this tutorial, we’ll create a data pipeline using Python and SQL. We’ll work with web server logs to extract information about visitors.
- Steps:
- Extract: Retrieve data from web server logs (e.g., Nginx logs).
- Transform: Clean, enrich, and format the data.
- Load: Store the transformed data for analysis.
- Use Case: Understanding visitor behavior on a website.
- Example: Extracting details like IP addresses, requested URLs, user agents, and response codes from log files.
2. Data Pipeline in Python:
-
- Definition: A series of data processing steps that convert raw data into actionable insights.
- Steps:
- Collect: Gather data from various sources.
- Clean Up: Remove inconsistencies, handle missing values, and standardize formats.
- Validate: Ensure data quality and accuracy.
- Convert: Transform data into a suitable format for analysis and reporting.
3. Pandas Pipelines:
-
- Description: Pandas allows the creation of data processing pipelines by chaining user-defined Python functions.
- Methods:
- Using
.pipe(): String together functions to build a pipeline. - Using
pdpipepackage: Import and use this package for pipeline construction.
- Using
4. Course: Building a Data Pipeline:
-
- Description: Learn how to create robust data pipelines with Python. These automated chains of operations save time and eliminate repetitive tasks.
- Skills Covered:
- Writing data pipelines.
- Scheduling tasks using Python.
- Versatility of the Python programming language.
Remember, Python provides powerful libraries and tools for data manipulation and pipeline creation. Whether you’re working with web logs, sensor data, or business transactions, Python’s flexibility makes it an excellent choice for building effective data pipelines
Pipeline Seaworld Opening Date
The Pipeline: The Surf Coaster at SeaWorld Orlando officially opened to the public in May 2023 as the world’s first surf coaster! 🌊🎢
Here are some exciting details about this unique roller coaster:
- Description: Pipeline is a one-of-a-kind attraction that makes you feel like you’re riding ocean waves on a giant surfboard, reaching speeds over 60 mph!
- Height: Riders must be at least 54 inches tall to experience the thrill unaccompanied.
- Dynamic Seats: Innovative dynamic seats allow you to feel every bank and curve as if you’re truly riding the waves.
- Location: You’ll find Pipeline at 7007 Sea World Dr, Orlando, FL, 32821.
For coaster enthusiasts, this addition to the Coaster Capital of Orlando is a must-ride! 🏄♂️🎡
Remember these surf lingo terms:
- Amped: Feeling excited and pumped up.
- Barrel: Refers to the curl of the wave or the hollow part when it breaks.
- Hang Loose: A friendly salutation often accompanied by the “Shaka” sign.
- Stoked: Extremely happy and excited.
Get ready to catch the virtual wave with a ride on Pipeline! 🌊🎡🎢
For more updates, follow SeaWorld Orlando on social media:
- Facebook: @SeaWorldOrlando
- Instagram: @SeaWorldOrlando
- Twitter: @SeaWorld
And yes, an annual pass grants you unlimited access to Pipeline: The Surf Coaster and all other attractions within the park for an entire year. Hang loose and enjoy the ride!
AWA Data Pipeline vs Glue
Let’s compare AWS Data Pipeline and AWS Glue to understand their differences and use cases:
1. AWS Data Pipeline:
-
- Purpose: AWS Data Pipeline is designed to simplify the management of data workflows. It allows you to focus on generating insights from your data by minimizing the development and maintenance effort required for daily data operations.
- Functionality:
- Workflow Orchestration: Data Pipeline orchestrates and automates complex data workflows.
- Execution Environment: Provides flexibility in terms of the execution environment.
- Control Over Compute Resources: Allows access and control over the compute resources that run your code.
- Data Processing Code: Provides access and control over the data processing code.
- Key Features:
- Workflow Design: Primarily focused on designing data workflows.
- Reliability: Runs on a highly reliable, fault-tolerant infrastructure.
- Use Cases:
- Ideal for scenarios where you need to manage complex data workflows and dependencies.
- Suitable for situations where you want to create custom data pipelines with specific business logic.
2. AWS Glue:
-
- Purpose: AWS Glue is more focused on ETL (Extract, Transform, Load) tasks. It provides automatic code generation and a centralized metadata catalog for managing data transformations.
- Functionality:
- Data Cataloging: Focuses on data cataloging and metadata management.
- Data Preparation: Provides tools for data preparation and transformation.
- ETL Automation: Automatically generates ETL code.
- Key Features:
- End-to-End Coverage: Provides more comprehensive coverage for data pipelines compared to Data Pipeline.
- Ongoing Enhancements: AWS continues to enhance Glue.
- Use Cases:
- Use Glue when you need an end-to-end solution for ETL tasks.
- Opt for Glue if you want automatic code generation and a centralized metadata catalog.
In summary, AWS Data Pipeline is best suited for orchestrating and automating complex data workflows, while AWS Glue is more focused on ETL tasks and provides features like automatic code generation and metadata management. Choose the one that aligns with your specific requirements!
What are Kafka Data Pipeline Benefits?
Salesforce Data Pipelines
Salesforce Data Pipelines is a powerful integration tool within Salesforce CRM Analytics (formerly known as Tableau CRM). Let’s dive into what it offers:
1. High-Performance Data Platform:
-
- Purpose: Salesforce Data Pipelines is designed to clean, transform, and enrich large volumes of data at scale.
- In-Platform Solution: Unlike external ETL (Extract, Transform, Load) tools, Data Pipelines is natively integrated into your trusted Salesforce environment. No need to shuttle data back and forth through external systems.
2. Key Features:
-
- Data Enrichment: Use Data Pipelines to enrich and modify Salesforce data without relying on third-party tools.
- Connector Ecosystem: It provides prebuilt connectors to access data from external systems like Snowflake, Amazon S3, and more.
- Recipes for Data Preparation: Create recipes to prepare large amounts of Salesforce and external data before loading it into Salesforce objects. Define data preparation logic, perform calculations, and clean up inconsistent formats.
- Smart Transformations: Predict missing values, detect text sentiment, and forecast key metrics using smart transformations.
- Query API Endpoint: If your recipes write results to datasets, you can query them using the Query API endpoint. This supports both SAQL and SQL queries.
3. Use Cases:
-
- Consolidating Data: If your CRM data is scattered across multiple systems, Data Pipelines helps consolidate it into one system (Salesforce).
- External Data Integration: Bring in data from external services and sync it with Salesforce.
- Enhancing Insights: When you have more data to work with, you gain richer insights.
In summary, Salesforce Data Pipelines empowers you to efficiently manage and enhance your data within Salesforce, making it a valuable tool for data integration and preparation
Stripe Data Pipeline

Stripe Data Pipeline is a powerful tool that simplifies data synchronization and integration for businesses using Stripe, a popular payment processing platform. Let’s explore its features and benefits:
1. Automated Data Delivery:
-
- Purpose: Stripe Data Pipeline allows you to sync your up-to-date Stripe data and reports directly to your data warehouse (such as Snowflake or Amazon Redshift) with just a few clicks.
- Efficiency: Set up the pipeline in minutes, and it will automatically deliver your Stripe data on an ongoing basis—no manual coding required.
2. Centralized Data:
-
- Single Source of Truth: By centralizing your Stripe data alongside other business data, you create a reliable source for financial reporting and analytics.
- Insights: Access richer insights by combining Stripe data with other relevant information.
3. Security and Reliability:
-
- Minimized Security Risks: Data Pipeline sends your Stripe data directly to your data warehouse, bypassing third-party ETL (Extract, Transform, Load) pipelines.
- Built into Stripe: Since it’s built into Stripe’s platform, you avoid data outages and delays.
4. Use Cases:
-
- Financial Close: Speed up your financial close process by having accurate, up-to-date data readily available.
- Payment Analysis: Identify the best-performing payment methods and analyze fraud patterns by location.
- Business Optimization: Optimize sales and marketing campaigns based on real-time data1.
In summary, Stripe Data Pipeline streamlines data synchronization enhances security, and empowers businesses with actionable insights—all while seamlessly integrating with Stripe’s financial platform
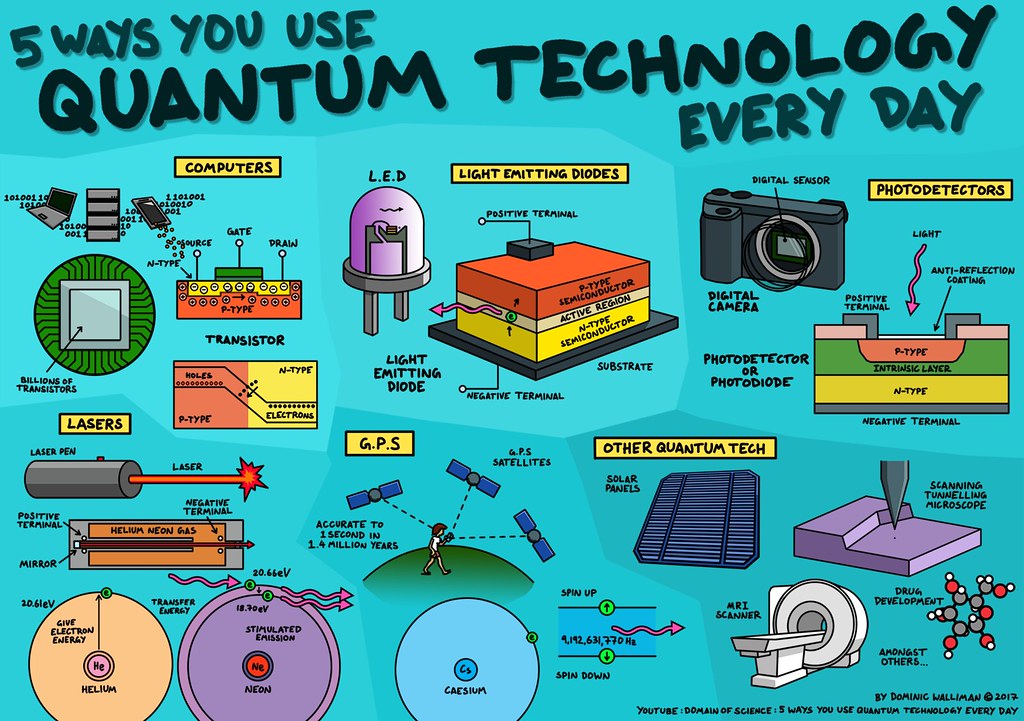
Streaming Data Pipeline
Let’s explore streaming data pipelines, which play a crucial role in handling real-time data ingestion, processing, and movement. These pipelines enable organizations to work with continuously fresh data, making it available for transformation, enrichment, and analysis. Here’s what you need to know:
1. What Are Streaming Data Pipelines?
-
- Streaming data pipelines move data from multiple sources to multiple target destinations in real-time.
- They capture events as they are created, ensuring that the data is always up-to-date.
- Examples of applications that rely on real-time data include:
- Mobile banking apps: Providing live transaction updates.
- GPS apps: Recommending driving routes based on live traffic information.
- Smartwatches: Tracking steps and heart rate in real-time.
- Personalized recommendations: In shopping or entertainment apps.
- Factory sensors: Monitoring conditions to prevent safety incidents.
2. Why Use Streaming Data Pipelines?
-
- Real-Time Insights: By moving and transforming data as it happens, these pipelines provide the latest, most accurate data.
- Agility: Organizations can respond intelligently to real-time events, reducing risk and enabling better-informed decisions.
- Revenue and Cost Savings: Real-time data helps generate more revenue and identify cost-saving opportunities.
- Personalized Customer Experiences: Delivering timely and relevant information to users.
- Stream Processing: Unlike batch processing, stream processing minimizes data latency by continuously transforming data en route to target systems. Use cases include real-time fraud detection.
In summary, streaming data pipelines are the connecting pieces in a real-time data architecture. They keep data sinks in sync with data sources, ensuring that organizations can work with fresh, actionable data for various use cases.
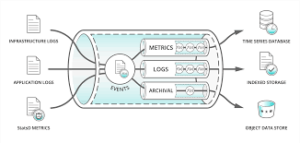
What is Data Pipeline Automation?
What is Data Pipeline Monitoring?
Data pipeline monitoring tools are software applications designed to monitor the performance, metrics, and status of data pipelines. They facilitate tracking and alerting mechanisms, ensuring the smooth operation of complex data processes and providing visibility into their health, efficiency, and overall performance.
What is Data Pipeline Design?
A data pipeline is a series of interconnected components that automate the collection, organization, movement, transformation, and processing of data from its source to a destination. The purpose is to ensure that the data is delivered in a usable state, enabling businesses to foster a data-driven culture.
- Storing data
- Using data for analytics
These services often include features for data ingestion, transformation, orchestration, monitoring, and integration with various data sources and destinations, streamlining the data pipeline development process.
What is Data Pipeline Observability?
How do I define an Automated Data Pipeline?
An automated data pipeline is a system designed to autonomously transfer data from one source to another, even when utilizing different platforms or technologies. It involves a series of procedures that collect data from various sources, perform data preparation and transformation, and subsequently load it into a destination for further analysis or other purposes.
What is a Data Pipeline Engineer?
A data engineering pipeline is a collection of tools and processes that facilitate the movement of data from one system to another, to store and manage the data. Data engineers play a central role in constructing and maintaining these pipelines, which involves writing scripts to automate recurring tasks, commonly referred to as jobs.
Why Data Pipeline Framework?
A data pipeline framework is a user-friendly solution that facilitates the monitoring, optimization, and orchestration of data processing tasks. It plays a crucial role in data engineering by enabling the import and processing of data from diverse sources into a centralized storage or analysis system. This process forms the basis of effective data management, as it converts raw data into valuable insights for decision-making.
CDE Data Pipeline, explain?
CDE (Cloud Data Engineering) data pipeline is a framework for building data pipelines in the cloud environment. It provides tools and services to extract, transform, and load (ETL) data from various sources into a cloud-based data warehouse or analytics platform, enabling efficient data processing and analysis in the cloud.
What is the Standard for Data Pipeline ETL?
ETL, which stands for “extract, transform, and load,” is a methodology employed by organizations to merge data from various sources into a unified database, data warehouse, data lake, or data store. ETL involves applying business rules to transform raw data, making it suitable for storage, data analytics, and machine learning (ML) purposes.
What is GCP Data Pipeline?
A machine learning data pipeline in Google Cloud Platform (GCP) refers to an integrated framework that leverages the native services provided by GCP to design and execute end-to-end machine learning workflows. It enables customers to utilize various GCP tools and services for building, training, and processing machine learning models. More detailed information can be found in the documentation on “Creating a machine learning pipeline.”
What is a Machine Learning Data Pipeline?
A machine learning (ML) pipeline is a collection of tools that streamline the process of extracting data from various sources and transforming it into a model that can be analyzed to generate desired outputs. It serves as an automated workflow that encompasses multiple sequential stages, including data extraction, preprocessing, model training, and deployment.
What is a DBT Data Pipeline?
DBT (Data Build Tool) is an open-source tool that enables users to define data models using SQL and automatically generates optimized SQL code for integration with data storage systems. It also automates the creation of documentation, lineage graphs, and tests for models. DBT facilitates a SQL-centric transformation workflow, allowing data teams to efficiently deploy analytics code while adhering to software engineering best practices such as modularity, portability, continuous integration/continuous deployment (CI/CD), and documentation. With DBT, all members of the data team can confidently contribute to the development of production-grade data pipelines.
What is a Serverless Data Pipeline?
A serverless data pipeline (SDP) refers to a series of serverless functions that process data in a pipeline fashion. Within a serverless computing environment, these functions can be triggered by specific events and operate on input data, performing necessary processing tasks before generating output.