ETL data pipelines enhance data quality and support various use cases like cloud migration, database replication, and data warehousing. ETL data pipelines can be easily set up using data integration tools, particularly through low-code and no-code platforms. These platforms offer graphical user interfaces (GUIs) that enable users to build and automate ETL pipelines, simplifying the flow of data within the organization.
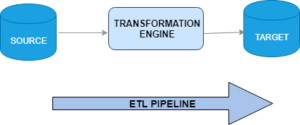
- Extract: Retrieve data from various sources, including databases, XML files, or cloud platforms.
- Transform: Modify the data’s format or structure to align with the desired system.
- Load: Integrate the transformed data into the target system, which may be a database, data warehouse, application, or cloud data warehouse.
ETL (Extract, Transform, Load) data pipelines play a crucial role in enhancing data quality, benefiting organizations across various use cases such as cloud migration, database replication, and data warehousing.
These pipelines automate the process of gathering information from multiple sources and then transforming and consolidating it into a central data repository. For instance, social media and video platforms utilize ETL pipelines to handle vast amounts of data, enabling them to gain insights into user behavior and preferences. This information empowers them to optimize their services, deliver personalized recommendations, and execute targeted marketing campaigns.
Furthermore, ETL pipelines contribute to streamlining data engineering and development tasks by facilitating rapid, no-code pipeline setup. This reduces the workload on data professionals, allowing them to focus on more critical responsibilities.
According to Gartner, organizations incur an average cost of $12.9 million annually due to poor data quality. Implementing robust ETL pipelines helps mitigate this issue by ensuring data accuracy, consistency, and reliability, leading to better-informed decision-making and improved operational efficiency.
Types of ETL Data Pipelines
ETL data pipelines can be classified into three types based on how data extraction tools retrieve data from the source.
Batch processing
This type of ETL data pipeline is known as batch extraction. In this approach, data is extracted from the source systems in predefined batches based on a scheduled synchronization set by the developer. This allows for a controlled server load, as the extraction occurs at specific times during the sync, reducing overall resource consumption.
Stream data integration (SDI)
In Streaming Data Integration (SDI), the data extraction tool continuously extracts data from its sources and streams it to a staging environment. Stream processing is a valuable approach for organizations dealing with substantial amounts of data that require continuous extraction, transformation, and loading. This type of ETL data pipeline is particularly beneficial in scenarios where data needs to be processed in real-time or near real-time, enabling organizations to handle large volumes of data streams efficiently.
ETL Pipeline Use Cases
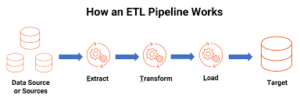
ETL data pipeline
ETL Pipeline vs Data Pipeline:
The term “data pipeline” encompasses the entire set of processes involved in moving and processing data from one system to another, whereas “ETL pipeline” specifically refers to the extraction, transformation, and loading of data into a database like a data warehouse. ETL pipelines are a specific type of data pipeline that includes these transformation and loading steps. However, a data pipeline can have different variations and may not always involve data transformation or loading into a database. It can encompass various processes and workflows depending on the specific use case and requirements.

- Focus: ETL specifically refers to the process of extracting data from source systems, transforming it to meet the target system’s requirements, and loading it into a destination system (e.g., data warehouse).
- Purpose: ETL pipelines are primarily used to prepare data for analytics and business intelligence by converting, cleansing, and integrating data from multiple sources.
- Data Transformation: ETL pipelines involve significant data transformation and often require dedicated infrastructure, such as ETL servers or tools, to process and shape the data.
- Structured Data: ETL is best suited for structured data that can be represented in tables and follows a predefined schema.
Data Pipeline:
- Focus: A data pipeline is a broader concept that encompasses the entire set of processes involved in moving and processing data from one system to another.
- Purpose: Data pipelines serve various purposes beyond preparing data for analytics, such as data migration, replication, synchronization, real-time data streaming, or data integration for different applications.
- Data Transformation: Data pipelines may or may not involve significant data transformation. Some pipelines simply move data from source to destination without altering its structure, while others perform transformations as needed.
- Data Variety: Data pipelines can handle a variety of data types, including structured, semi-structured, and unstructured data, such as text, images, or sensor data.
ETL Data Pipeline Tools
Hadoop distributions offer various tools for ETL, such as Hive and Spark. These solutions provide powerful and scalable capabilities, supporting structured and unstructured data processing. Additionally, they offer elasticity, allowing users to pay only for the resources utilized, making it cost-effective.
- Data integration: The tool’s capability to connect to multiple data sources and destinations.
- Customizability: The extent to which the tool can be customized to fit specific requirements and workflows.
- Cost: Consideration of the tool’s cost, including infrastructure and resources for ongoing maintenance and support.