
What is AWS Data Pipelines?
AWS Data Pipeline is a web service provided by Amazon Web Services (AWS) that enables the automation of data movement and transformation. AWS Data Pipeline is a web service used for automating data movement and transformation between AWS services and on-premises data sources. It enables the creation of data-driven workflows with task dependencies, ensuring tasks are executed in the correct order. Here are the key points about AWS Data Pipeline:

1. Purpose:
-
- Automate Data Workflows: AWS Data Pipeline allows you to define data-driven workflows. These workflows specify how data should move between different AWS services and even on-premises data sources.
- Dependency Management: You can set up tasks to be dependent on the successful completion of previous tasks, ensuring proper sequencing.
2. Features:
-
- Workflow Definitions: You create workflow definitions that describe how data flows through your pipeline. These definitions include data sources, destinations, transformations, and scheduling.
- Data Transformation: AWS Data Pipeline supports logic-based data transformations. You can specify how data should be transformed or optimized based on different conditions.
- Scheduled Execution: Data movement and transformations occur at specified intervals (e.g., hourly, daily, weekly).
3. Use Cases:
-
- ETL (Extract, Transform, Load): AWS Data Pipeline is commonly used for ETL processes, where data is extracted from various sources, transformed, and loaded into a target system.
- Data Migration: It facilitates data migration between different AWS services or from on-premises systems to AWS.
- Regular Data Updates: If you need to update data periodically (e.g., syncing data from a database to Amazon S3), AWS Data Pipeline can handle it.
4. Comparison with Other Services:
-
- Amazon Glue: While both AWS Data Pipeline and Amazon Glue are used for ETL, Glue is more focused on serverless data preparation and transformation.
- AWS Step Functions: Step Functions provide more complex workflow orchestration capabilities beyond data movement.
AWS Data Pipeline Examples:
AWS Data Pipeline is a powerful service for automating data workflows. Let’s explore some common examples of how it can be used:
1. Archiving Web Server Logs:
-
- Suppose you run a web server, and you want to archive your server logs to Amazon S3 daily.
- You can set up an AWS Data Pipeline to copy the logs from your server to an S3 bucket every day.
- Additionally, you might want to run a weekly Amazon EMR (Elastic MapReduce) cluster over those logs to generate traffic reports. AWS Data Pipeline can schedule this weekly EMR task.
2. Exporting MySQL Data to Amazon S3:
-
- If you have a MySQL database containing valuable data, you can use AWS Data Pipeline to export that data to an S3 bucket.
- Define a pipeline that connects to your MySQL database, extracts the necessary data, and stores it securely in S3.
- This process can be automated on a regular basis (e.g., daily or weekly).
3. Copying Data Between Amazon S3 Buckets:
-
- Imagine you have data stored in one S3 bucket, and you need to replicate it in another bucket.
- AWS Data Pipeline allows you to create a workflow that periodically copies data from one S3 bucket to another.
- You can set the frequency (e.g., hourly, daily) based on your requirements.
4. Data Transformation and Aggregation:
-
- Suppose you collect data from various sources (e.g., logs, databases, APIs) and need to transform and aggregate it.
- AWS Data Pipeline can orchestrate the entire process:
- Extract data from different sources.
- Transform it using Amazon EMR, AWS Lambda, or other services.
- Load the transformed data into a target system (e.g., Redshift, RDS, Elasticsearch).
5. Regular Data Updates:
-
- If you have data that needs to be updated periodically (e.g., product inventory, financial data), AWS Data Pipeline can handle it.
- Define a pipeline that fetches the latest data from your source (database, API, flat files) and updates the target system.
- Set the schedule according to your business needs.
AWS Data Pipeline Architecture Example
In an AWS Data Pipeline architecture example, data can be extracted from an on-premises database, transformed using AWS services like AWS Lambda or AWS Glue, and then loaded into an Amazon S3 bucket or a database such as Amazon Redshift. This process can be orchestrated and scheduled using AWS Data Pipeline’s workflow capabilities.
1. Data Extraction: The pipeline starts by extracting data from an on-premises database using a data source such as JDBC or AWS Database Migration Service.
2. Data Transformation: The extracted data is then transformed using AWS services like AWS Lambda or AWS Glue. This can involve cleaning, filtering, aggregating, or joining the data to prepare it for the desired output.
3. Data Loading: The transformed data is loaded into an Amazon S3 bucket, which provides scalable object storage, or into a database like Amazon Redshift, which offers powerful analytics capabilities.
4. Workflow Orchestration: Amazon Data Pipeline manages the workflow orchestration, ensuring that each step in the pipeline is executed in the correct order and handling dependencies between tasks. It provides scheduling, monitoring, and error-handling capabilities.
AWS Data Flow:
Both AWS and Google Cloud offer data flow solutions for building efficient data pipelines. Whether you’re using Amazon SageMaker Data Wrangler, Google Cloud Dataflow, or integrating with other services, data flows play a crucial role in managing and transforming data!
Let’s explore AWS Data Flow and its significance:
1. Amazon SageMaker Data Wrangler Flow:
-
- Purpose: Amazon SageMaker Data Wrangler provides a visual interface for creating and modifying data preparation pipelines.
- Data Flow: A data flow (or Data Wrangler flow) is a sequence of steps that connect datasets, transformations, and analyses. It defines how data moves through the pipeline.
- Instance Types:
- When creating a Data Wrangler flow, you can choose an Amazon EC2 instance type to run the analyses and transformations.
- Available instances include m5 (general purpose) and r5 (optimized for large datasets in memory).
- Opt for an instance that best suits your workload.
- Switching Instance Types:
- You can seamlessly switch the instance type associated with your flow.
- To do so, navigate to the instance you’re using, select the desired type, and save the changes.
- Remember to shut down unused instances to avoid additional charges1.
- Exporting Data Flow:
- When exporting your data flow (e.g., to Amazon S3 or SageMaker Feature Store), Data Wrangler runs an Amazon SageMaker processing job.
- Choose the appropriate instance for the processing job based on your requirements.
2. Google Cloud Dataflow:
-
- Managed Service: Google Cloud Dataflow is a managed service for executing various data processing patterns.
- Deployment: It allows you to deploy batch and streaming data processing pipelines.
- Documentation: You can find detailed instructions on deploying Dataflow pipelines on the Google Cloud Dataflow documentation.
3. Integration with Amazon AppFlow:
-
- Amazon AppFlow integrates AWS services with SaaS apps like Salesforce, Slack, and Marketo.
- It simplifies data transfer between AWS and SaaS applications, making it easier for developers.
AWS Data Pipeline vs Glue:
AWS Glue is a serverless data integration service offered by Amazon Web Services (AWS). It enables users to prepare, discover, move, and combine data from various sources, making it suitable for tasks such as machine learning, analytics, and application development. With AWS Glue, users can easily create and run ETL (Extract, Transform, Load) jobs through a user-friendly interface in the AWS Management Console.
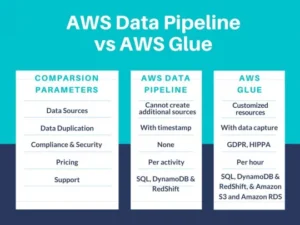
AWS Glue:
- Purpose: AWS Glue is more focused on ETL (Extract, Transform, Load) tasks. It provides automatic code generation and a centralized metadata catalog for managing data transformations.
- Data Cataloging: Focuses on data cataloging and data preparation.
- Dependency Management: While it does provide scheduling capabilities, it does not offer the same level of dependency management as AWS Data Pipeline.
- Coverage: Provides more end-to-end data pipeline coverage than Data Pipeline.
- Development: AWS continues to enhance Glue, whereas development on Data Pipeline appears to be stalled
AWS Glue vs AWS Data Pipeline
- AWS Data Pipeline emphasizes workflow management and data movement.
- AWS Glue focuses on data cataloging, ETL, and data preparation.
- Choose based on your specific needs: simplicity (Glue) or more control over workflows (Data Pipeline).
AWS Data Pipeline Pricing
The pricing for AWS Data Pipeline is as follows:
- Active Pipeline Cost: You pay $1.00 per active pipeline per month. If your AWS account is less than 12 months old, you are eligible to use the free tier, which provides one free active pipeline each month.
- Additional Charges: In addition to the active pipeline cost, there may be additional charges for storing data and accessing the pipeline.
Remember that AWS Data Pipeline allows you to automate the movement and transformation of data, defining data-driven workflows with dependencies on successful task completion. It’s a powerful tool for managing data workflows in the cloud!
AWS Data Pipeline Documentation
You can find detailed information about AWS Data Pipeline in the official AWS Data Pipeline Documentation. This documentation covers various aspects of AWS Data Pipeline, including:
1. Developer Guide:
-
- Provides a conceptual overview of the AWS Data Pipeline.
- Includes detailed development instructions for using the various features.
- Explains how to define data-driven workflows, where tasks can be dependent on the successful completion of previous tasks.
2. API Reference:
-
- Describes all the API operations for AWS Data Pipeline in detail.
- Provides sample requests, responses, and errors for the supported web services protocols.
Additionally, if you’re interested in more insights and practical strategies for designing, implementing, and troubleshooting data pipelines on AWS, you might find this guide helpful: Demystifying Data Pipelines: A Guide for Developers on AWS
AWS Data Pipeline Deprecation
AWS Data Pipeline, a managed service that provides a simple and scalable way to orchestrate data movement and transformation, is indeed changing. Let me clarify the details for you:
1. Maintenance Mode and Console Access Removal:
-
- The AWS Data Pipeline service is currently in maintenance mode. As part of this, console access to the service will be removed on April 30, 2023. After this date, you won’t be able to access AWS Data Pipeline through the console.
- However, you will still have access to AWS Data Pipeline via the command line interface (CLI) and API.
2. Service Deprecation:
-
- While there was some confusion earlier, it’s now clear that AWS Data Pipeline is not being deprecated entirely. It is expected to remain available in the near future.
3. Alternatives:
-
- If you’re currently using AWS Data Pipeline and need an alternative solution, consider the following options:
- AWS Glue: AWS Glue is a fully managed extract, transform, and load (ETL) service that can handle data preparation and transformation tasks.
- AWS Step Functions: Step Functions allow you to coordinate multiple AWS services into serverless workflows.
- Amazon Managed Workflows for Apache Airflow: This service provides managed Apache Airflow workflows.
- If you’re currently using AWS Data Pipeline and need an alternative solution, consider the following options:
AWS Data Pipeline Icon
you can find the official AWS Data Pipeline icon in the AWS Simple Icons repository, which is a collection of icons representing various AWS services. The AWS Simple Icons can be accessed and downloaded from the following link:
AWS Simple Icons: https://aws.amazon.com/architecture/icons/
Once on the AWS Simple Icons page, you can search for “Data Pipeline” in the search bar or navigate through the available categories to locate the specific icon for AWS Data Pipeline.
AWS Data Pipeline vs Azure Data Factory
In summary, if you prioritize ease of use, administration, and ongoing support, Azure Data Factory might be a better fit for your business needs. However, consider your specific requirements and evaluate both options to make an informed choice.
1. Purpose and Functionality:
-
- AWS Data Pipeline:
- Provides a managed service for orchestrating data movement and transformation.
- Supports data workflows across various AWS services and on-premises data sources.
- Azure Data Factory:
- Enables seamless data integration from diverse data sources.
- Transforms data to meet business requirements.
- AWS Data Pipeline:
2. Ease of Use and Administration:
-
- Reviewers found Azure Data Factory easier to use, set up, and administer.
- Overall, they preferred doing business with Azure Data Factory.
3. Quality of Support and Product Direction:
-
- Reviewers felt that Azure Data Factory provides better ongoing product support.
- They also preferred the direction of Azure Data Factory for feature updates and roadmaps.
4. Pricing:
-
- AWS Data Pipeline pricing is based on data flow execution, pipeline orchestration, and the number of data factory operations.
- Azure Data Factory pricing is flexible, and you only pay for what you need.
5. Ratings:
-
- AWS Data Pipeline: 4.1/5 stars with 24 reviews.
- Azure Data Factory: 4.6/5 stars with 74 reviews.
AWS Data Pipeline vs Step Functions
AWS Data Pipeline is primarily focused on data-centric workflows and ETL processes, while AWS Step Functions provide a broader range of capabilities for building and coordinating complex workflows.
1. Workflow Execution Model:
-
- AWS Data Pipeline: It follows a pipeline-based model, where tasks are organized into a linear sequence of steps, and dependencies between tasks are defined.
- AWS Step Functions: It uses a state machine model, where workflows are defined as a series of states, and transitions between states are determined based on the outcomes of previous states.
2. Task Complexity and Expressiveness:
-
- AWS Data Pipeline: It supports a wide range of AWS services and provides flexibility in integrating different data sources and performing data transformations. However, it may require additional services like AWS Lambda or AWS Glue for advanced data processing.
- AWS Step Functions: It offers more flexibility and expressiveness in defining complex workflows, including conditional branching, parallelism, and error handling. It can orchestrate not only AWS services but also custom code running on AWS or external systems.
How to Get AWS Data Pipeline




